

1. Introduction
Every year, millions of road accidents claim lives and cause life-altering injuries — and the leading cause is not mechanical failure. It is the human factor: fatigue, distraction, and slow reaction times. A drowsy driver, a glance at a phone, or a missed vehicle ahead can all be the difference between a safe journey and a tragedy.
Advanced Driver Assistance Systems (ADAS) have long been a feature of premium vehicles, but embedding real-time AI-powered monitoring directly at the edge — on affordable hardware — is changing the game. This post walks through the design, architecture, and results of a Smart Driver Monitoring and ADAS System built using computer vision and deep learning.
The system addresses two parallel challenges simultaneously: understanding what the driver is doing (drowsiness, distraction, phone use) and understanding what is happening on the road ahead (vehicle detection, distance estimation, collision risk). Running entirely on an edge AI device, it delivers real-time warnings with minimal latency — no cloud dependency required.
2. Use Case
The core problem this system solves is deceptively simple to state but technically demanding to implement: how do you continuously monitor a driver and the road ahead in real time, on a single embedded device, and generate meaningful safety alerts before an incident occurs?
The Scenario
Imagine a long-haul truck driver on a night route, or a rideshare driver in heavy traffic. Fatigue sets in gradually. The head starts drooping. Eyes flutter. Attention drifts. A vehicle ahead slows suddenly. These are the moments where a system that can see, analyze, and alert — all within milliseconds — can prevent disaster.
This project targets exactly these scenarios. The system is designed to:
• Detect early signs of drowsiness before the driver fully falls asleep
• Catch distraction caused by head turning away from the road
• Identify mobile phone usage — one of the leading causes of accidents
• Monitor the gap to the vehicle ahead and estimate time to collision
• Alert the driver in real time through a dashboard display
3. Real-World Scenario
4. Solution Design / Architecture
The system is built around two parallel AI pipelines — one focused on the driver, one on the road — both processing video frames in real time on an embedded GPU platform.
4.1 System Overview
Rather than using dedicated hardware cameras, this prototype uses two accessible and cost-effective video sources that closely mirror a real-world deployment. A mobile phone acting as an IP webcam provides the driver-facing video stream, connected over a local WiFi network to the Jetson Orin Nano. The front road camera is simulated using a pre-recorded dashcam video file, played back in real time to represent the forward view of the vehicle. Both streams are ingested, preprocessed (resized, color-converted, and synchronized), and dispatched to the AI inference pipeline. This approach allowed the full system to be developed and validated without requiring dedicated embedded cameras, making it practical for a lab or prototype environment while keeping the architecture identical to a production deployment.
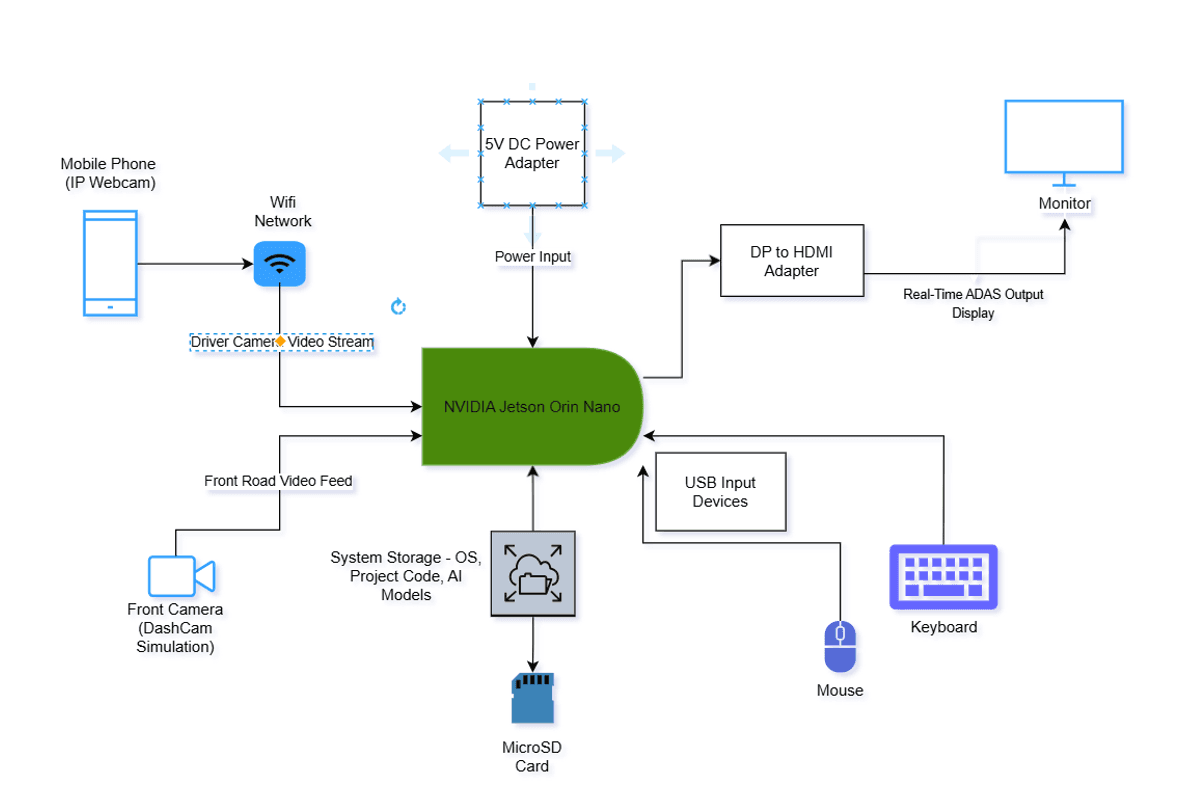
System hardware architecture — NVIDIA Jetson Orin Nano as the central processing hub, connected to a mobile phone IP webcam (driver feed via WiFi), a front dashcam simulation video, a MicroSD card for storage, and a monitor for real-time ADAS output.
4.2 Driver Monitoring Pipeline
The driver monitoring module uses MediaPipe's facial landmark detection to extract precise facial keypoints in real time.
Drowsiness Detection — Eye Aspect Ratio (EAR)
Eye closure is measured using the Eye Aspect Ratio (EAR), computed from six eye landmark coordinates. The formula captures the ratio of vertical to horizontal eye opening:
EAR = (||p2−p6|| + ||p3−p5||) / (2 × ||p1−p4||)
When EAR drops below a threshold and remains there across multiple consecutive frames, the driver is classified as drowsy and an alert is triggered. This approach is robust to natural blinking while reliably catching prolonged eye closure.
Head Pose Detection — Yaw Angle
Distraction is detected by estimating the 3D orientation of the driver's head using facial landmarks. The yaw angle — the degree of left/right rotation — is computed via a PnP solver. When the head turns beyond a defined angle threshold for a sustained duration, the driver is flagged as distracted.
Phone Usage Detection
A YOLOv8 object detection model is deployed to identify mobile phones within the driver's area. When a phone is detected near the driver's hands or face across multiple frames, an alert is raised. The model is optimized with TensorRT for low-latency inference.
4.3 Collision Risk Pipeline
The front camera feeds into a separate detection and estimation pipeline:
Vehicle Detection
YOLOv8 detects vehicles in the front camera feed, providing bounding box coordinates for each detected object. The model runs asynchronously to maintain smooth video display.
Distance Estimation — Pinhole Camera Model
Distance to the leading vehicle is estimated using the pinhole camera model:
Distance = (Real Object Width × Focal Length) / Bounding Box Width
With a calibrated focal length and a known approximate vehicle width, this formula provides a real-time distance estimate without requiring LIDAR or stereo cameras.
Time to Collision (TTC)
Relative speed between frames is computed by comparing distance estimates across time. TTC is then derived as:
TTC = Distance / Relative Speed
When TTC falls below a safety threshold, a collision warning is displayed to the driver.
4.4 Performance Optimizations
Achieving real-time performance on an embedded platform required several optimizations:
• TensorRT Acceleration: YOLOv8 models were converted to TensorRT engines, dramatically reducing GPU inference time
• Multithreaded Video Capture: Each camera stream runs on its own thread, eliminating capture bottlenecks
• Resolution Optimization: Frames are downscaled to reduce compute load while preserving detection accuracy
• Asynchronous Inference: Object detection runs at intervals while video display remains smooth and continuous
4.5 The Hardware Platform: NVIDIA Jetson Nano
All of this AI inference — dual-stream video processing, object detection, facial landmark tracking, and collision estimation — runs on a single NVIDIA Jetson Orin Nano. Understanding this device helps explain both the promise and the constraints of the system.
What Is the Jetson Nano?
The NVIDIA Jetson Nano is a compact, power-efficient System on Module (SOM) designed specifically for edge AI workloads. At just 70 x 45mm — smaller than a credit card — it packs the GPU compute needed to run modern deep learning models locally, without any connection to a cloud server. It was built for exactly the kind of application described in this project: real-time video analysis on embedded hardware with strict power and size constraints.
"Bring incredible new capabilities to millions of edge devices" — NVIDIA's vision for the Jetson Nano captures exactly what this ADAS project demonstrates in practice.
Key Specifications
Component | Details |
AI Performance | 472 GFLOPs (FP16) — sufficient for multiple concurrent neural networks |
GPU | 128-core NVIDIA Maxwell architecture GPU |
CPU | Quad-core ARM Cortex-A57 @ 1.43 GHz |
Memory | 4 GB 64-bit LPDDR4 @ 25.6 GB/s |
Power Consumption | 5W – 10W configurable (fanless or active cooling) |
Form Factor | 70 x 45 mm SOM — smaller than a credit card |
Camera Support | Up to 4 cameras via MIPI CSI-2 |
Connectivity | Gigabit Ethernet, USB 3.0, HDMI 2.0, GPIO headers |
Software Stack | JetPack SDK, CUDA, cuDNN, TensorRT, OpenCV |
5. Key Findings
Building and testing this system surfaced several important technical and practical insights:
EAR Thresholds Require Calibration
The EAR threshold for drowsiness detection is not universal. Differences in facial geometry, glasses, lighting conditions, and camera angle all affect the raw EAR value. A fixed threshold works well for demonstration purposes, but production systems should implement per-driver calibration or adaptive thresholds.
Distance Estimation Accuracy Depends on Calibration
The pinhole camera model provides reliable relative distance estimates, but absolute accuracy depends on correct focal length calibration and assumptions about vehicle width. For production use, a calibration step and more robust object size priors would improve accuracy, particularly for non-standard vehicle types.
TensorRT Delivers Substantial Speedups
Converting the YOLOv8 model to a TensorRT engine yielded significant inference acceleration on the embedded GPU. This optimization was essential to achieving real-time performance and demonstrates that edge AI inference optimization is as important as model selection.
Multi-Pipeline Design is Critical
Running driver monitoring and road monitoring on separate, asynchronous pipelines prevents either stream from blocking the other. This architectural decision was crucial for maintaining responsiveness across both monitoring tasks simultaneously.
False Positive Management Matters
Short-duration alerts (triggered by a single frame) led to disruptive false positives during testing. Implementing frame-count thresholds — requiring an alert condition to persist across N frames before triggering — significantly improved the signal-to-noise ratio of the warnings.
6. Results / Impact
The implemented system successfully demonstrates a complete, real-time embedded AI safety platform. The key outcomes include:
Capability | Outcome |
Real-Time Driver Monitoring | Continuous, low-latency detection of drowsiness, distraction, and phone use from a live camera feed |
Collision Risk Prediction | Distance and TTC estimation from a single front camera, without LIDAR or stereo vision |
Edge AI Inference | Full pipeline running on an embedded GPU platform with TensorRT-accelerated models |
Multi-State Classification | Five driver states detected: Attentive, Drowsy, Distracted, Phone Usage, Collision Warning |
No Cloud Dependency | All processing on-device, enabling deployment in areas with limited connectivity |
Beyond technical benchmarks, the broader impact of a system like this is measured in lives. Studies by NHTSA and Euro NCAP consistently show that early warning systems reduce accident rates by 20–40% in fleet deployments. Bringing these capabilities to edge hardware at low cost means the technology can reach commercial vehicles, public transport, and developing markets — not just premium consumer vehicles.
7. Call to Action
The tools to build systems like this have never been more accessible. YOLOv8, MediaPipe, and TensorRT are all open-source or freely available. Edge AI platforms like the NVIDIA Jetson family bring GPU inference to embedded deployments at under $100. The barrier to building a functioning ADAS prototype has dropped dramatically.
Try It Yourself
If you want to experiment with the core components of this system:
• Start with MediaPipe's Face Mesh solution to extract facial landmarks and implement your own EAR-based drowsiness detector
• Use the Ultralytics YOLOv8 Python API to run object detection on a webcam feed in under 10 lines of code
• Explore TensorRT's Python API to accelerate your models on NVIDIA hardware
• Combine them into a unified pipeline and test with pre-recorded driving video before moving to live feeds
Go Deeper
To build on the foundations of this project, explore these areas:
• Gaze tracking for more precise attention monitoring beyond head yaw
• Sensor fusion combining camera data with IMU and GPS for richer context
• Federated learning techniques for improving models across a fleet while preserving driver privacy
• Integration with CAN bus data for speed-aware collision thresholds
Join the Conversation
Road safety is a shared challenge — and AI-powered assistance systems are one of the most promising tools we have to address it. If you are working on related problems, building ADAS solutions, or exploring edge AI applications in safety-critical domains, we would love to connect.